|
Shreyas Verma Hi there! I am Gen AI Research Scientist at Asurion based out of San Francisco,CA . I work with a small team of passionate AI Engineers working towards redefining customer tech troubleshooting industry using Agentic AI. At Asurion, I have worked extensively on building production-grade Conversational AI Agents. I have led research efforts on solving the "latency problem" of an AI chatbot with efficient memory management,robust semantic caching, parallelization of guardrail prompts and optimizing RAG pipelines. I also interned as an Applied Scientist with the Search & Discovery AI team at Zillow, where I worked on building Multimodal Representations for homes using contrastive learning techniques - considerably improving upon the Similar Homes downstream recommendation task. I am completed my Master's degree in Computational Data Science from Georgia Tech in 2023 and my Bachelors in Engineering degree from BITS Pilani. Email / Resume / Google Scholar / LinkedIn |

|
ResearchI am passionate about working towards building efficient Small Language Models (SLMs). I have hands-on experience with creating mid-training as well as post-training LLM Alignment pipelines for tech support domain. I have worked extensively towards building as well as contributing to state-of-the-art LLM benchmarks for evaluations as well as creating synthetic datasets. |
|
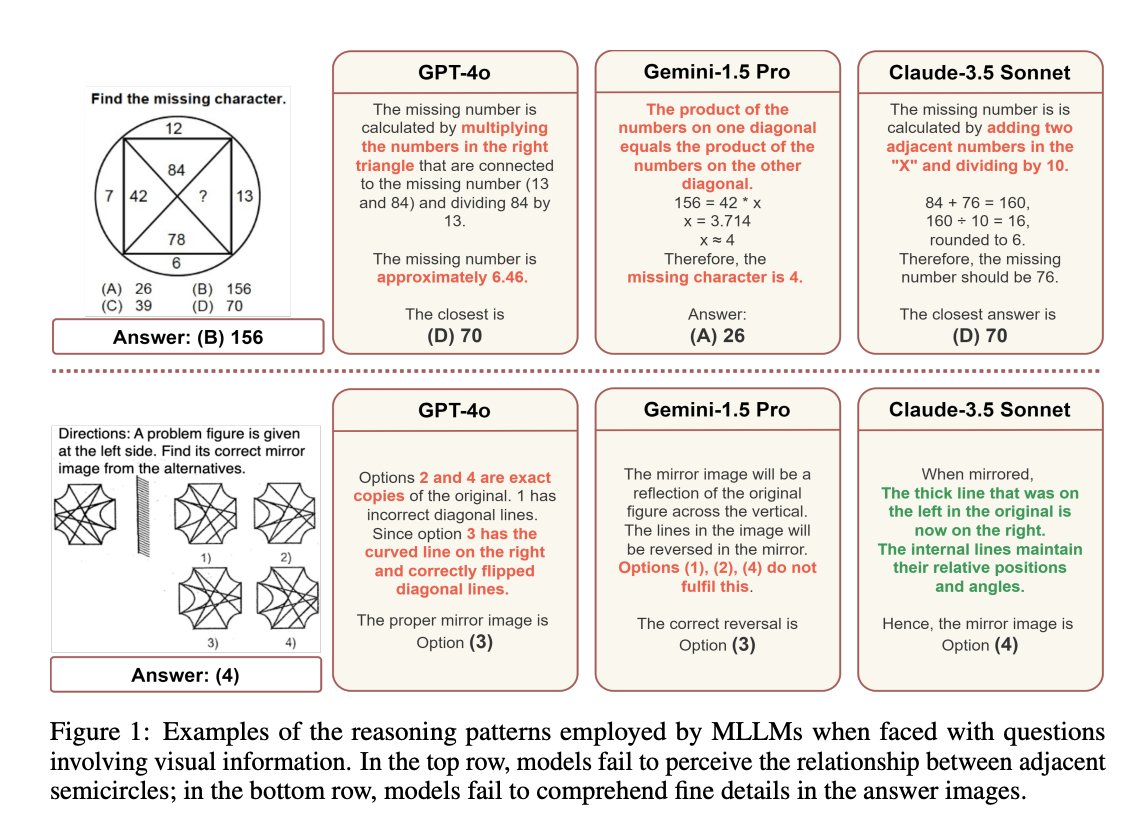
Polymath: A Challenging Multi-modal Mathematical Reasoning Benchmark
Himanshu Gupta, Shreyas Verma, Ujjwala Anantheswaran, Kevin Scaria, Mihir Parmar, Swaroop Mishra, Chitta Baral arXiv / website / code / dataset A challenging benchmark aimed at evaluating the general cognitive reasoning abilities of Multi-modal Large Language Models (MLLMs), PolyMATH comprises 5,000 manually collected high-quality images of cognitive textual and visual challenges across 10 distinct categories, including pattern recognition, spatial reasoning, and relative reasoning. |
|
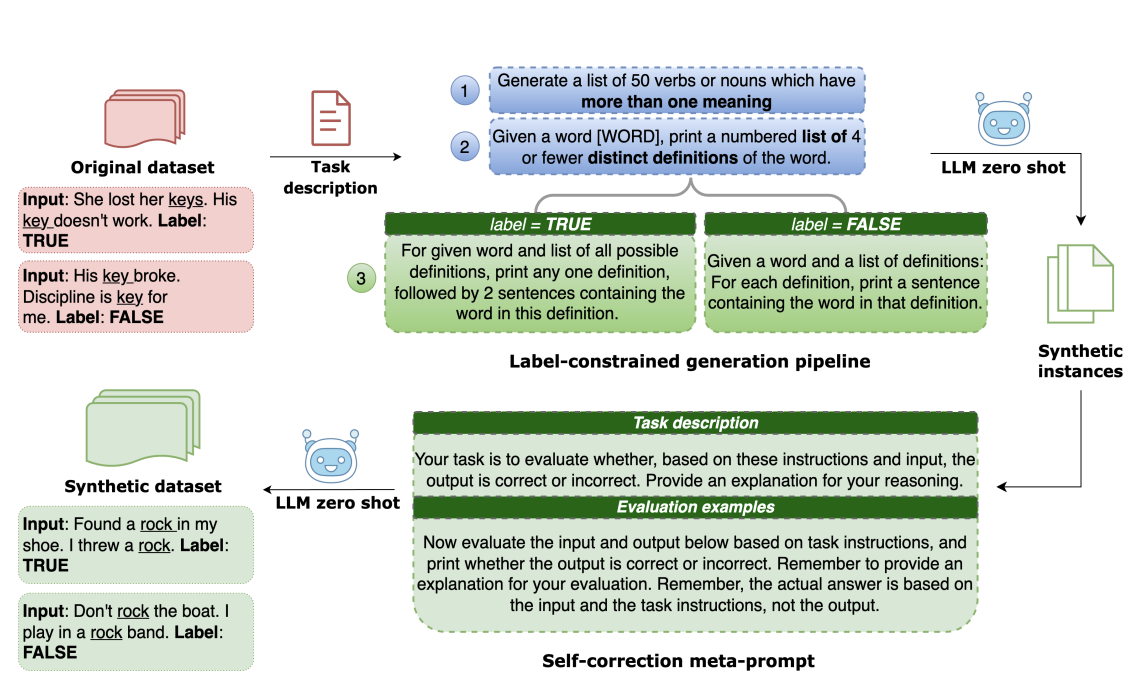
TarGEN: Targeted Data Generation with Large Language Models
Himanshu Gupta, Ujjwala Anantheswaran, Kevin Scaria, Shreyas Verma, Mihir Parmar, Swaroop Mishra, Chitta Baral CoLM, 2024 arXiv In this paper, we present TarGEN, a multi-step prompting strategy for generating high-quality synthetic datasets utilizing a LLM. An advantage of TarGEN is its seedless nature; it does not require specific task instances, broadening its applicability beyond task replication. |
|
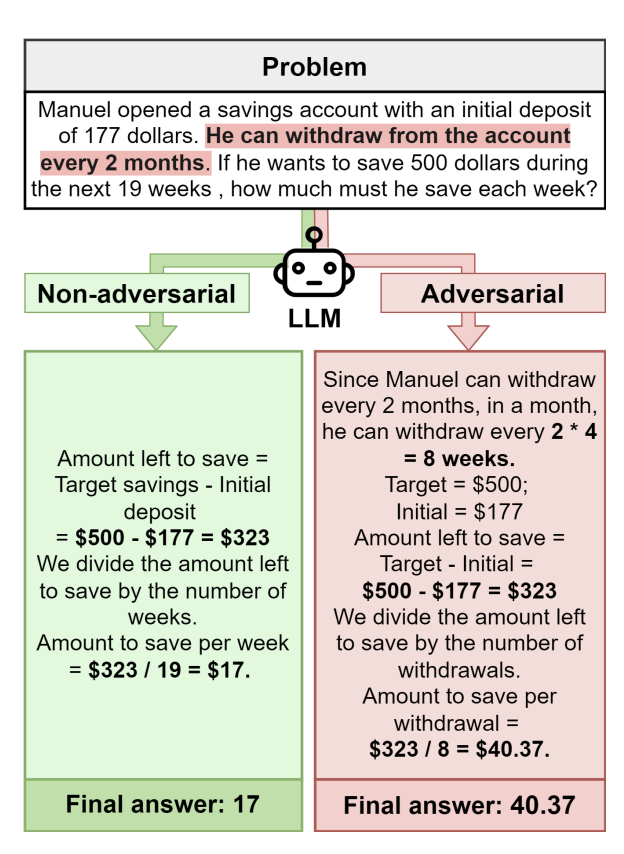
Cutting Through the Noise: Boosting LLM Performance on Math Word Problems
Himanshu Gupta, Ujjwala Anantheswaran, Kevin Scaria, Shreyas Verma, Mihir Parmar, Swaroop Mishra, Chitta Baral ICLR (Workshop), 2025 arXiv Large Language Models (LLMs) excel at various tasks, including solving math word problems (MWPs), but struggle with real-world problems containing irrelevant information. To address this, we propose a prompting framework that generates adversarial variants of MWPs by adding irrelevant variables. We introduce a dataset, PROBLEMATHIC, containing both adversarial and non-adversarial MWPs. |
|
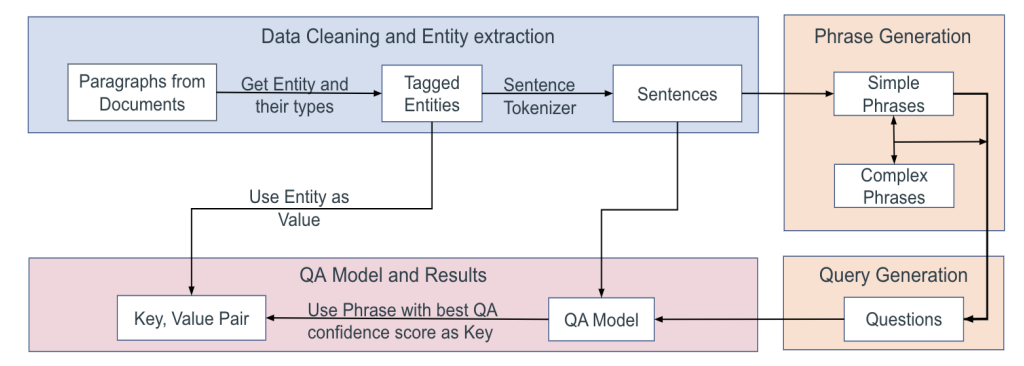
CONTEXT-NER: Contextual Phrase Generation at Scale
Himanshu Gupta, Shreyas Verma, Swaroop Mishra NeurIPS (Workshop), 2022 arXiv Named Entity Recognition (NER) has seen significant progress in recent years, with numerous state-of-the-art (SOTA) models achieving high performance. However, very few studies have focused on the generation of entities’ context. In this paper, we introduce CONTEXT-NER, a task that aims to generate the relevant context for entities in a sentence, where the context is a phrase describing the entity but not necessarily present in the sentence. |
Miscellanea |
|
Design and source code from Jon Barron's website |